Using Bayesian Posterior Distributions to Aid in the Measurement of Individualized, Evidence-Based Learning (MIEBL) for Applied Behavioral Analysis Therapy
Last updated: May 30, 2026
Children with both level 2 autism and global developmental delay typically have difficulty understanding, retaining, and generalizing instruction, especially when it is language-dense and multi‑step. For example, washing one’s hands in the sink. They often require highly structured and repetitive instruction with frequent prompting and opportunities for practice.
This is the underlying principle behind discrete trial training (DTT), one of the many tools used in applied behavioral analysis (ABA) therapy for helping such children develop. An important aspect of DTT is the performance criterion – what the student needs to achieve in order for the practitioner to decide that they have “learned” the task and can move on to the next one.
In more traditional classroom instruction, this is parallel to concepts of testing and grading. Yet it is different because traditional approaches emphasize group-based standards and norm-referenced performance, which can work well for relatively homogeneous learners, but not so when students need to be focused on individually in one-on-one instruction like in ABA interventions. Thus, the only data that practitioners can use when deciding on whether the student has learned enough of a task is activity in the student’s own daily sessions which are meticulously documented.
For example, a student may be considered to have learned washing hands if they were observed to do so independently at least 80% of the time in a single session. However, such performance criteria bestow probabilistic confidence differently depending on factors that are within the practitioner’s control. In particular, the number of trials matters – a performance criterion that requires students to do 8 out of 10 is more reliable than one that requires 4 out of 5, despite both being 80% criteria.
This is a basic lesson in probability and statistics, and is specifically shown when applying a Bayesian beta-binomial posterior distribution. Motivated by this, we proposed the Measurement of Individualized, Evidence-Based Learning (MIEBL) models for DTT, which leverage Bayesian reasoning to help practitioners decide on what performance criteria to use when inferring about the latent level of mastery the student has over the task. In the linked paper, we mainly wanted to communicate to practitioners how much changing their number of trials matters for the same performance criteria, which helps not just in how they apply DTT, but also explains variability in the performance that they observe when doing research.
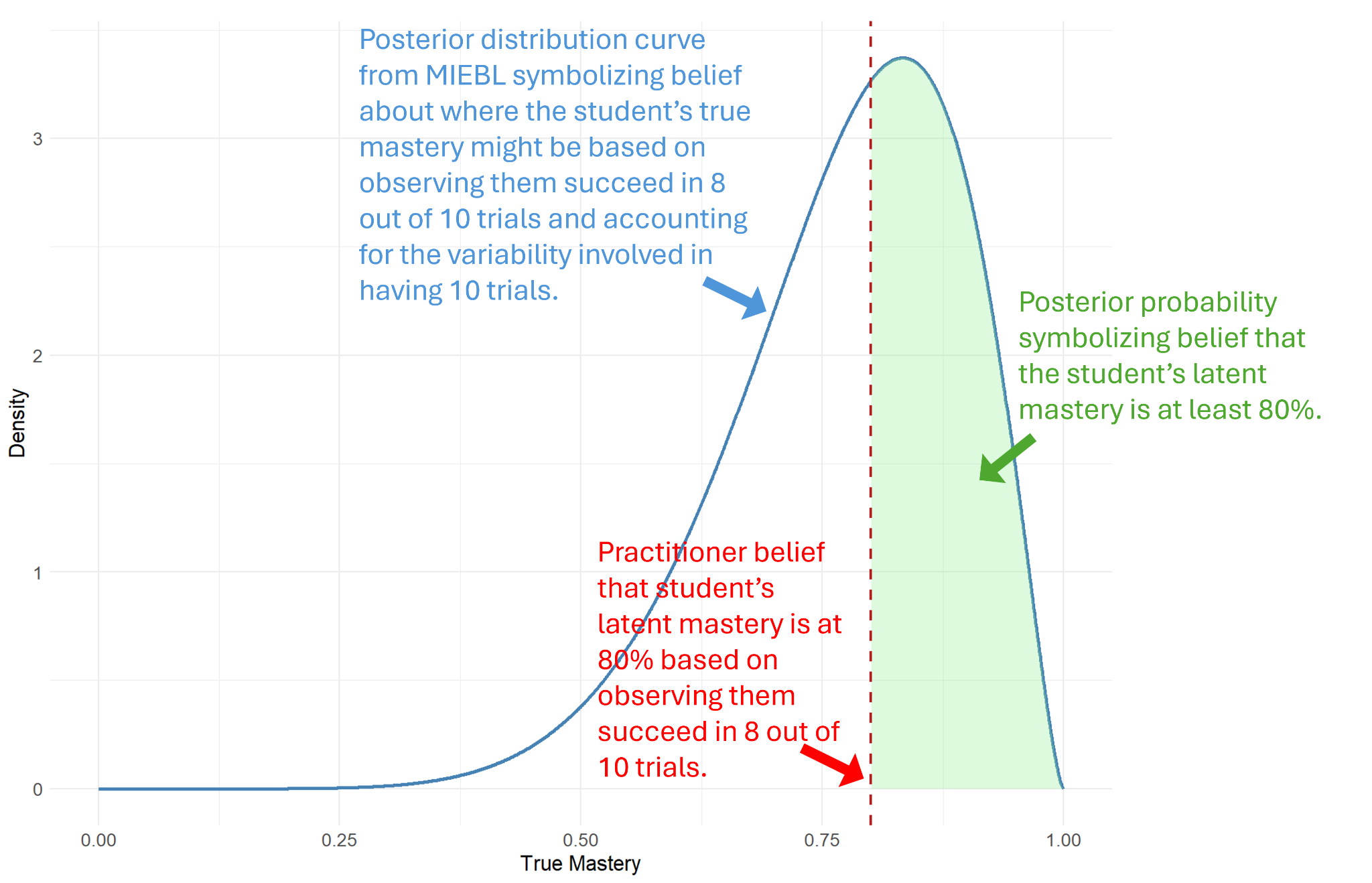
If you are a new student of Bayesian inference, this is a good example of how even the humble beta-binomial can be used to help practitioners in another field of work in a way that is both intuitive and meaningful. From this basic model, we are presently expanding our approach to incorporate learner activity beyond a single session.
In practice, performance criteria used actually cover performance across multiple sessions. For example, a common criterion used is observing the student perform successfully at 80% per session across three consecutive sessions. Estimating the posterior distribution of latent ability in this setting requires consideration of various elements, such as how to account for learning that happens from session to session, and how to consider chance occurrence of the performance criterion even when latent mastery is low when the time horizon to potentially observe it is too long.
This is work in progress with Dr. Reetam Majumder from the Department of Mathematical Sciences at the University of Arkansas and Dr. Ji Young Kim and Dr. Jonathan Ivy from the School of Behavioral Sciences and Education at The Pennsylvania State University. We have a working RShiny app prototype (linked here), and I can conduct orientations for practitioners on how they can use this in their practice.
About the Author
Mark Louie F. Ramos is an Assistant Research Professor of Health Policy and Administration at The Pennsylvania State University. He completed his doctorate in Statistics at the University of Maryland Baltimore County and received postdoctoral training at the Biostatistics Branch of the National Cancer Institute. Prior to this, he was a tenured faculty member at the University of Santo Tomas, Manila. He has been teaching mathematics and statistics subjects from grade school to graduate school levels since 2004.
References
- Booth, N., & Keenan, M. (2018). Discrete Trial Teaching: A study on the comparison of three training strategies. Interdisciplinary Education and Psychology, 2(2). https://doi.org/10.31532/InterdiscipEducPsychol.2.2.003
- Kim, J. Y., Fienup, D. M., Draus, C. J., & Wong, K. K. (2023). Differential mastery criteria impact sight word acquisition and maintenance: Application to individual operants and teaching trial doses. Journal of Applied Behavior Analysis, 56(2), 388–399. https://doi.org/10.1002/jaba.970
- Majumder, R., Ramos, M., Kim, J., & Ivy, J. (2026). Multi-session trial mastery. https://reetamm.shinyapps.io/MIEBL/
- Richling, S. M., Williams, W. L., & Carr, J. E. (2019). The effects of different mastery criteria on the skill maintenance of children with developmental disabilities. Journal of Applied Behavior Analysis, 52(3), 701–717. https://doi.org/10.1002/jaba.580
- Ramos, M. (2025). MIEBL: Measurement of Individualized, Evidence-Based Learning Criteria Designed for Discrete Trial Training. Behavior Analysis in Practice. https://doi.org/10.1007/s40617-025-01058-9
- Schneider, A., Fienup, D. M., Gussin, R., & Moss, P. (2022). A preliminary comparison of mastery criterion frequency values: Effects on acquisition and maintenance. Behavioral Interventions, 37(2), 306–322. https://doi.org/10.1002/bin.1834